
All Resources
Tokenmaxxing: Why just burning through tokens won’t make you better at AI


by Tess Robinson
There is a new status game playing out in the tech industry and it has a name: tokenmaxxing.
Tokenmaxxing describes the practice of deliberately maximising your AI token consumption by burning through as many interactions with AI tools as humanly possible, on the premise that heavy usage signals productivity, commitment and AI-nativeness. It spread through Silicon Valley earlier this year before reaching mainstream headlines in April, when reports emerged of companies at Meta, OpenAI and Shopify tracking internal leaderboards of who burns the most tokens. One Disney employee reportedly interacted with an AI tool 460,000 times in nine days (ridiculous!!). Shopify's Head of Engineering, Farhan Thawar, told The Pragmatic Engineer podcast that the company actively celebrated the people using the most tokens: "I want to see why they spent $1,000 a month in credits. Maybe that's because they're building something great."
It's a compelling (if expensive and don’t get me started on the environmental cost) idea and it isn't entirely wrong.

The part that works
There are some things that tokenmaxxing gets right, because there is genuine learning logic buried inside it.
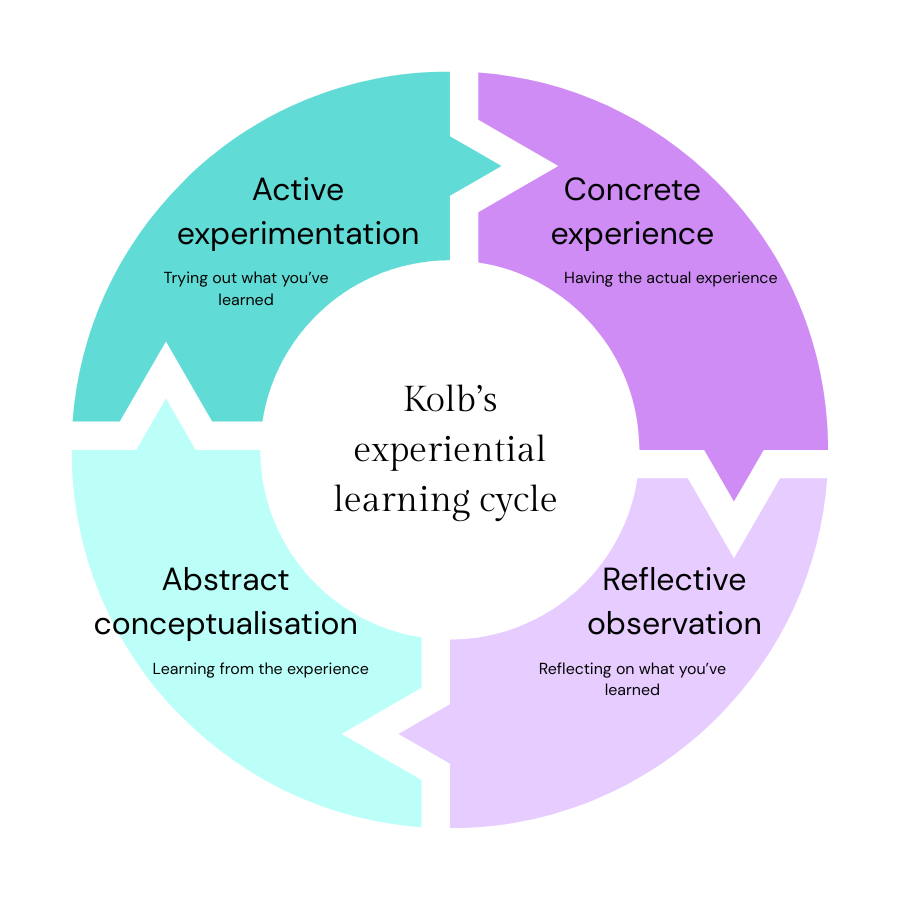
For people who have never really pushed AI tools to their limits, sheer volume of use does create something valuable: exposure. You encounter more of what the tools can and can't do. You stumble across use cases you'd never have thought to try. You build intuitions that you simply can’t develop by watching a webinar or reading a guide. In learning and development terms, this maps neatly onto Kolb's Experiential Learning Cycle, which describes how meaningful learning begins with a concrete experience. You have to get your hands dirty before reflection, conceptualisation and intelligent experimentation can follow. Some of Kolb's work, particularly around learning styles, has been heavily critiqued over the years, but, in my opinion, his experiential learning cycle model, although fairly basic, still has some merit.
There's also something to be said for the psychological permission that tokenmaxxing implicitly gives. In organisations where people are worried about looking foolish with new technology or where admitting confusion feels like a professional risk, being told to just use it (a lot) can lower the psychological barrier to entry. Harvard Business School professor Amy Edmondson's work on psychological safety reminds us that people learn best when they feel safe to experiment and fail without judgment. A culture that says "try everything" is, at least, in spirit, friendlier to learning than one that says "only use it if you know what you're doing."
So yes, exploration matters. Hands-on experience matters. Getting people to move from passive awareness to active use is a real and important challenge. Tokenmaxxing, in its most charitable reading, is a blunt instrument for solving that problem.
The trouble is that blunt instruments cause collateral damage - number one being a massive bill with no real progress having been made.
When the metric becomes the mission
The British economist Charles Goodhart set out what is now known as Goodhart's Law in 1975: "When a measure becomes a target, it ceases to be a good measure." He was writing about monetary policy at the time, but the same principle applies with uncanny accuracy to tokenmaxxing.
The moment an organisation puts token usage on a leaderboard, it stops being a proxy for productivity and becomes a goal in itself. Employees, rationally, predictably, start optimising for the number rather than the outcome. Logan Wolfe, a partner at Kyndryl's AI strategy practice, put it plainly in a recent CIO magazine analysis: "Employees are de facto incentivised for using tokens or, in some cases, punished for not using enough tokens. And obviously, it's a metric that's very easy to game." He compared it to rewarding software developers for writing the most lines of code, a practice that reliably produces bloated, inefficient applications.
A New York Times investigation found that some of those self-declared tokenmaxxers were candid about the performative element: heavy usage was, at least in part, a "strategic way to signal to their bosses and colleagues that they're keeping up with the times." That's not learning. That's theatre.
This is where behavioural science becomes a useful lens. Self-Determination Theory, developed by Edward Deci and Richard Ryan, shows that extrinsic motivators (targets, leaderboards, performance metrics) tend to crowd out intrinsic motivation. The person who was genuinely curious about what AI could do for their work becomes a person focused on clocking up enough interactions to stay visible on the rankings. The curiosity, ironically, gets trained out of them.

What structured experimentation should actually look like
The antidote to tokenmaxxing isn't less experimentation. It's better experimentation. The kind that actually generates learning rather than just generating tokens.
Let’s go back to Kolb for a moment. His experiential learning cycle doesn't just begin with concrete experience, it moves through reflective observation, abstract conceptualisation, and active experimentation in sequence. The critical word is sequence. Tokenmaxxing short-circuits this. People accumulate experience but skip the reflection and conceptualisation stages. They never pause to ask: What did I learn from that? What would I do differently? What am I testing next?
Without those stages, the cycle doesn't close. Experience accumulates but true learning doesn't.
Structured experimentation, the kind that L&D professionals and behavioural scientists would recognise, looks different. It starts with a clearly defined question: not "how many times can I use this tool?" but "does using AI to draft my weekly report free up meaningful time and is the report of good enough quality?" It involves a hypothesis, a controlled test, a moment of reflection on what happened and a decision about what to try next based on that insight.

This is what separates high-quality learning from expensive noise. It's also the difference between organisations that genuinely improve their AI capability over time and those that simply accumulate impressive-looking usage statistics while their actual workflows remain unchanged.
Amy Edmondson also talked about "productive failure." The goal isn't a culture where people feel free to use AI randomly and constantly; it's a culture where they feel free to run small, deliberate experiments, reflect honestly on what worked and what didn't, and share those findings with their teams. That's where learning lives.
The L&D opportunity hiding in plain sight
For learning and development professionals, tokenmaxxing is a gift, not because it's good practice, but because it signals something genuinely important about where organisations are right now with AI adoption.
People are trying. They want to be seen to be trying. The motivation to engage with these tools is there, even if it's sometimes driven by status anxiety rather than genuine curiosity. That's a foundation to build on.
The L&D opportunity is to redirect that energy into something structured. To give people frameworks, not just unrestricted freedom. To design experiments alongside them, not just declare that experimentation is encouraged. To build in the reflective moments that tokenmaxxing skips. To treat AI capability not as a stat to be tracked but as a skill to be developed: one that, like all skills, requires deliberate practice, feedback, and iteration.
The organisations that will genuinely unlock the value of AI won't be the ones with the biggest token budgets or the highest usage rankings. They'll be the ones that have developed a culture of intelligent, evidence-based experimentation, where people know not just how to use the tools, but why they're using them, what they're learning and how that learning is changing the way they work.
Stay ahead
with our insights
Receive the latest strategies, trends, and innovative approaches directly in your inbox